

首先是造出一个 List
List<String> list = new ArrayList();
for(int i = 1; i<= 10000; i++) {
list.add(String.valueOf(i));
}
for(int i = 1; i<= 10000; i++) {
list.add(String.valueOf(i));
}
先看看我们用 contain 去重的代码:
StopWatch stopWatch = new StopWatch();
stopWatch.start();
System.out.println("contains 开始去重,条数:" + list.size());
List<String> testListDistinctResult = new ArrayList<>();
for (String str : list) {
if (!testListDistinctResult.contains(str)) {
testListDistinctResult.add(str);
}
}
System.out.println("contains 去重完毕,条数:" + testListDistinctResult.size());
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTime());
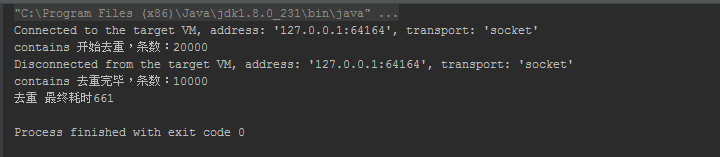
去重 最终耗时661毫秒
接下来使用HashSet去重
StopWatch stopWatch = new StopWatch();
stopWatch.start();
System.out.println("HashSet.add 开始去重,条数:" + list.size());
List<String> testListDistinctResult = new ArrayList<>(new HashSet(list));
System.out.println("HashSet.add 去重完毕,条数:" + testListDistinctResult.size());
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTime());
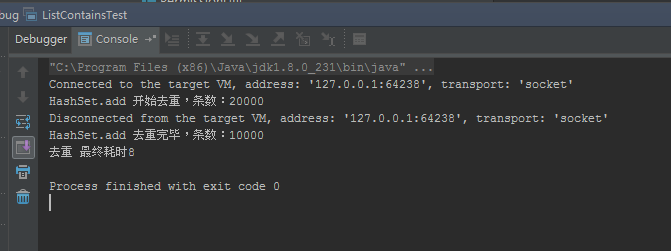
去重 最终耗时8毫秒
HashSet 的效率是相当高啊 建议List去重使用HashSet去做处理。
为什么耗时差距这么大?
不多说,我们看源码:
可以看到里面用到了 index(o) :
list.contains(o):
/**
* Returns <tt>true</tt> if this list contains the specified element.
* More formally, returns <tt>true</tt> if and only if this list contains
* at least one element <tt>e</tt> such that
* <tt>(o==null ? e==null : o.equals(e))</tt>.
*
* @param o element whose presence in this list is to be tested
* @return <tt>true</tt> if this list contains the specified element
*/
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
/**
* Returns the index of the first occurrence of the specified element
* in this list, or -1 if this list does not contain the element.
* More formally, returns the lowest index <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,
* or -1 if there is no such index.
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
循环重复判断去决定SIZE大小
接下来看看HashSet
时间复杂度 :O(n) n: 元素个数
那么我们看看 set.add(o) 是怎么样的 :
/**
* Constructs a new set containing the elements in the specified
* collection. The <tt>HashMap</tt> is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* {@inheritDoc}
*
* <p>This implementation iterates over the specified collection, and adds
* each object returned by the iterator to this collection, in turn.
*
* <p>Note that this implementation will throw an
* <tt>UnsupportedOperationException</tt> unless <tt>add</tt> is
* overridden (assuming the specified collection is non-empty).
*
* @throws UnsupportedOperationException {@inheritDoc}
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
* @throws IllegalArgumentException {@inheritDoc}
* @throws IllegalStateException {@inheritDoc}
*
* @see #add(Object)
*/
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}
map的add , 老生常谈就不谈了,hash完 直接塞到某个位置, 时间复杂度 :O(1) 。
所以 O(n) 和 O(1) 谁快谁慢?显然。